Understanding Parameter Estimation in the RW Model: A Deep Dive into Learning Rates and Predictive Accuracy
By Talent Navigator
Published Mar 1, 2025
5 min read
In the realm of cognitive psychology and behavioral science, understanding how organisms learn and adapt to their environment is crucial. One of the fascinating methods for exploring learning behavior is the RW (Rescorla-Wagner) model, which employs mathematical equations to predict the learning rate and accuracy of predictions based on specific parameters. This article delves into parameter estimation within the RW model, exploring its significance and main components, and will provide insights into how learning behaviors can be effectively quantified and predicted.
What is the RW Model?
The RW model is widely used in psychology to describe how individuals learn associations between stimuli and responses. It defines an objective function that quantifies prediction errors, allowing researchers to update specific model parameters and improve predictive accuracy.
Key Parameters of the RW Model
- Alpha (α): This represents the learning rate and determines how quickly new associations are formed. A higher alpha indicates a faster learning process.
- V: This is the prediction value, which evolves over the trials, adjusting as more data is collected.
- A: This is the stability factor, which signifies the strength of condition stimuli in attracting attention.
Optimizing these parameters ensures that the model accurately depicts learning behavior over time, providing insights into associative learning processes.
The Parameter Estimation Process
Optimization Techniques
Parameter estimation starts with selecting a randomly set of positive parameters. Through optimization algorithms, such as fmin search (a numerical method utilized in MATLAB), researchers can efficiently minimize the objective function's value, which typically corresponds to reducing prediction errors.
Understanding Objective Functions
- Objective Function: Represents the goal of optimization by quantifying prediction error.
- Goodness of Fit: This is assessed by comparing the model’s predictions against actual data to determine how accurately it reflects real-world learning behavior.
By fine-tuning constants like associability and learning rates (parameters A and α), researchers can discover the best fit for experimental data, aiming to minimize discrepancies between predicted and actual learning behavior.
Importance of Error Minimization
Using algorithms like fmin search allows for more effective optimization processes. The ultimate goal is to minimize errors, leading to more reliable predictions of how quickly and strongly organisms learn from their experiences.
Insights from Graphical Data
Data visualization is critical in understanding the impact of learning rates. For instance, graphs illustrating learning curves display how variations in alpha influence learning speed:
- With an alpha value of 0.5, learning progresses at a moderate pace.
- Increasing alpha to 3 exhibits a notably steeper decline in error, indicating faster learning.
- A further increase to 9 escalates the learning rate, providing an even sharper curve.
Key Observations:
- Higher alpha values lead to faster learning rates.
- The graphical representations reveal the relationship between learning rate adjustments and prediction efficacy.
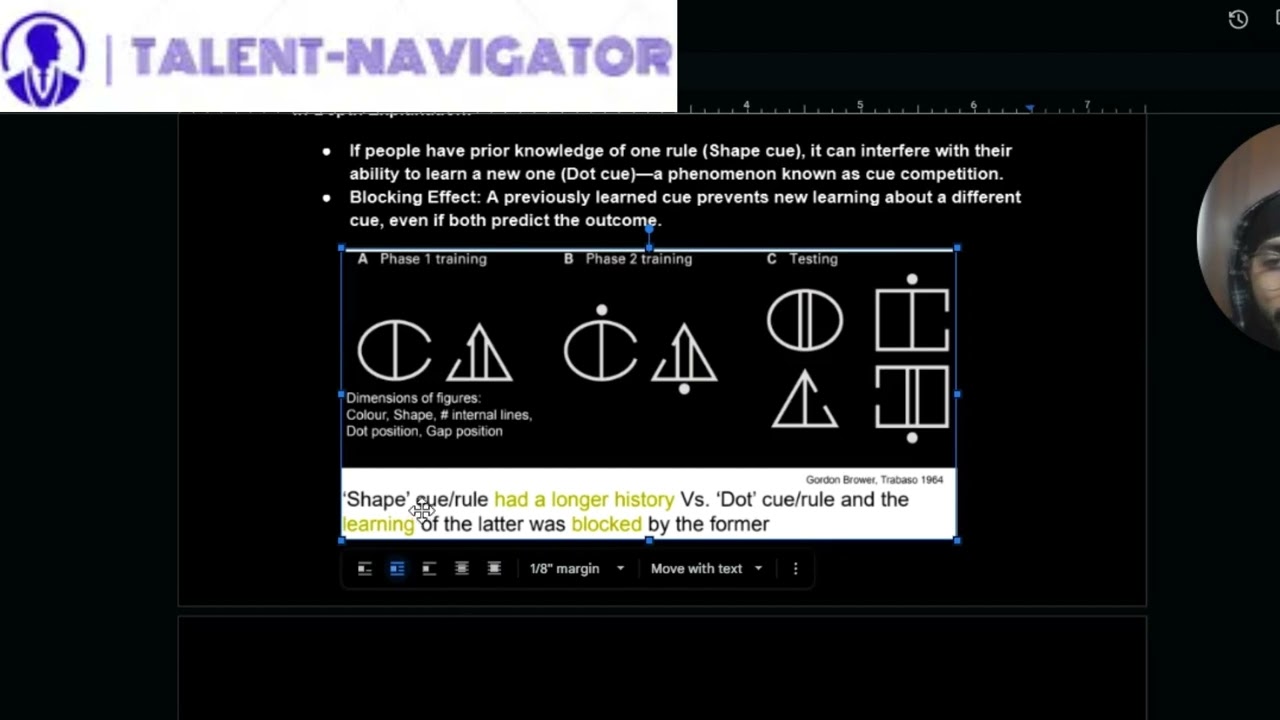
The Concept of Cue Competition
One significant aspect of the RW model involves understanding cue competition, which is highlighted by research from Gordon Brow and colleagues. They explored how the relevance and history of cues affect learning:
- Prior Knowledge: Participants trained with one cue (e.g., shape) found it difficult to learn a new cue (e.g., dot) due to blocking effects.
- Que Competition: This concept suggests that previously learned cues can inhibit the acquisition of new associated cues, even when both lead to the same outcome.
- Experiment Breakdown:
- Phase 1: Training with the shape cue.
- Phase 2: Training with both shape and dot cues.
- Testing phase: When tested on the dot cue alone, learning performance suffers due to interference from the shape cue.
Contextual Analysis of Learning
The RW model emphasizes that learning involves more than mere association; it incorporates factors such as attention and cue salience.
- Contextual Analysis D: This highlights that prior weights can impede new learning experiences, a phenomenon tied to latent inhibition. If one cue is familiar, it may overshadow new information or cues introduced later.
Summary of Key Takeaways:
- The learning process is significantly influenced by the strength and history of cues.
- Blocks due to prior learning demonstrate how acquired knowledge can disrupt future learning pathways.
- Effective learning is contingent on simplifying cues and removing redundant information to emphasize salient details.
Conclusion
In summary, the RW model's approach to parameter estimation offers valuable insights into the intricacies of learning behavior. By leveraging optimization techniques and understanding the dynamics of learning rates, researchers can enhance predictive accuracy, paving the way for more profound insights into educational practices and cognitive therapy.
Understanding how different factors, including cue interference and learning speed, play a role in learning equips educators and psychologists with the tools to cultivate improved learning environments.
For anyone interested in the scientific inquiry of learning and behavior, the RW model serves as a pivotal resource in exploring the predictive and adaptive nature of learning processes. Discover more about the implications of these theories and venture deeper into the fascinating world of cognitive psychology.
Engage with us in the comments! What are your thoughts on how prior knowledge impacts learning outcomes?



Comments
Post a Comment